Ola Electric Scooter Sentiment Analysis Using Reddit Data

Date: March 03, 2024
Introduction:
In the present world, technology is changing rapidly. In the last decade, a new technology has emerged that has caused a massive change in transportation. Electric vehicles are now seen everywhere. In India, the Electric vehicle revolution is not recent, but one company, OLA Electric, has made it more popular than ever. Ola Electric was separated from its parent company, “Ola Cabs”, 2017 and entirely focused on making electric vehicles (Lidhoo, 2021). Ola Electric acquired several battery-making and electric two-wheeler companies between 2017 and 2021. Ola Electric has also established the largest electric two-wheeler factory in India. In 2021(Bhalla, 2020; IndianWeb2, 2022), Ola Electric started producing electric two-wheeler vehicles. The first product of Ola Electric was a two-wheeler electric scooter. Now, Ola manufactures electric motorcycles, and the Ola Electric Car will soon be launched (CarDekho, 2024).
In India, electric vehicles have been used for a long time, but on a tiny scale. By manufacturing electric cars on a large scale, Ola Electric has become the pioneer in EVs in India. According to Government of India Press Information Bureau (2023), the Electric vehicle Industry in India will grow 49% by 2030. Now that electric vehicles are gaining so much popularity in India. It is essential to understand and evaluate the performance of these EVs on the honest judgement of customers.
In this report, a sentiment analysis of customers of Ola Electric’s first model of scooter is done. The first model of the scooter was launched around three years ago, and the expectation is to get a good amount of social media data on this model compared to any other. This sentiment analysis focuses on understanding the user experience of customers using electric scooters and underlining the advantages and disadvantages of using Ola scooters. The bigger picture is to capture the efficiency of EVs and their future.
Data:
In this report, Reddit is used to extract information. Reddit is a Social Media Platform where people share their experiences, ask questions, and participate in discussions. Thirty-three of the posts were chosen to extract comments from Reddit. This Post was filtered manually. All the posts chosen here were selected based on search terms where someone gave feedback on the Ola S1 scooter or asked for an opinion on this model. Figure 1 shows the search terms used for filtering out the data. This approach is used for data collection to maintain the topic’s relevance. Figure 2 shows all the relevant post URLs used for data collection.
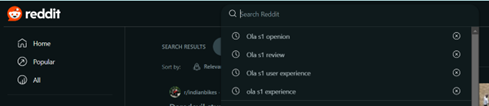
Figure: 1
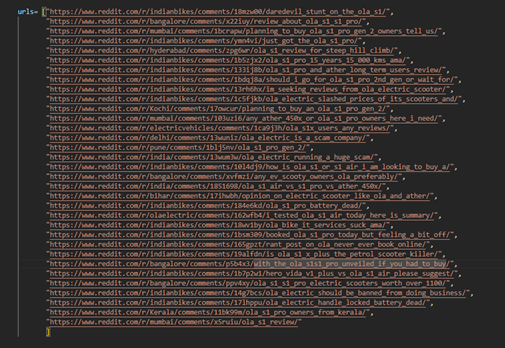
Figure: 2
Data Collection Procedure:
Python with a praw module is used to extract the data. Praw is the abbreviation of Python Reddit API Wrapper. Using Reddit, a developed app is created. Using the app’s client ID and client secret praw, fetch the comments directly from Reddit. A loop system is used to go into each URL individually and collect all the top-level and second-level comments with the date and time when they were posted, as shown in Figure 3. A total of 941 comments are collected. All the data is converted into a Pandas Data frame (as shown in Figure 4) for the subsequent phases of sentiment analysis.
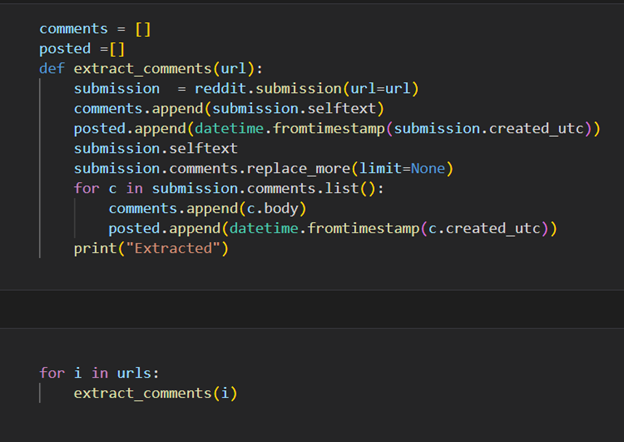
Figure: 3
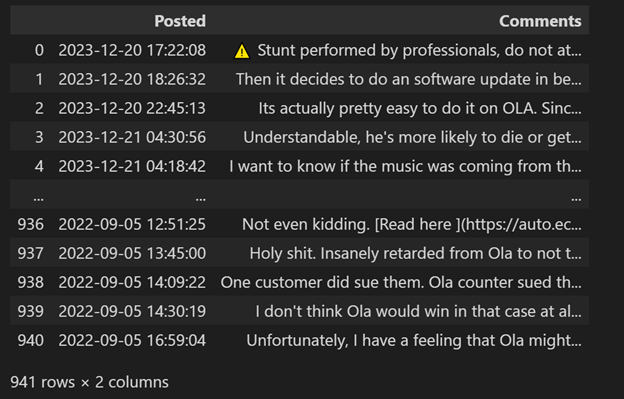
Figure: 4
Data Preparation:
After data collection, it is prepared by filtering and transforming the dataset into the required format. The posted column of the dataset contains all the date and time values, so its datatype is converted to datetime. All the comments are in different formats in the comment column, so to normalise the comments column, all comments are converted to lowercase. As shown in figure 5. In sentiment analysis, it is difficult to find the sentiment of a very small comment, so to increase the accuracy of analysis, correct sentiment comments with less than 15 words are removed, as shown in Figure 6. In the same way for the analysis, only one language is selected by first detecting the language and filtering out comments in English, only referred to in Figure 7. Then, contractions are expanded to include all the words used in short forms in the dataset. After filtering, the length of the dataset is reduced, and new columns (len: the size of the comment and lang: the language of the comment) are added to the dataset, as shown in Figure 8.

Figure: 5
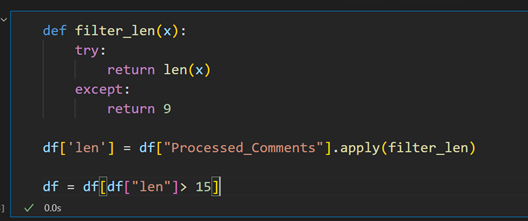
Figure: 6 
Figure: 7 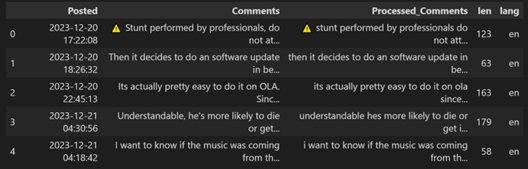
Figure: 8
2.3. Data Preprocessing: After cleaning the data, Data preprocessing steps are applied to filter all the comments to remove unnecessary words. There is a preprocessing pipeline is implemented where the steps of preprocessing pipelines are as follows:
Removing emojis (Figure 9):
Emojis can have useless interpretations that negatively impact the sentiment analysis models trained on text data. Removing them ensures the model focuses on the core words and their context.
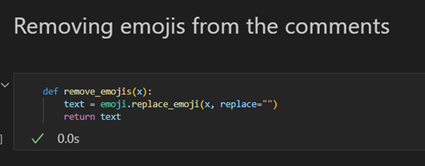
Figure: 9
Text substitution (Figure 10):
Text substitution addresses abbreviations, slang, or informal language that sentiment analysis models might not understand. It normalises the text for better model comprehension.
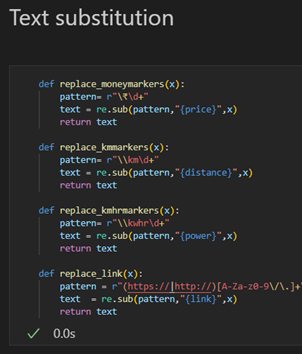
Figure: 10
Tokenization of Dataset (Figure 11):
Tokenisation breaks down the text into individual words (tokens) for more straightforward analysis. It allows the model to process the data word by word, building an understanding of sentiment.
Figure: 11
Removal of stopwords (Figure 12):
Stopwords are common words that don’t contribute much to sentiment. Removing them reduces noise and improves model focus on sentiment-carrying words.

Figure: 12
Lemmatization of text (Figure 13):
Lemmatisation reduces words to their base form. This helps capture the sentiment behind the same word, leading to a more accurate analysis.
Figure: 13
The pipeline helps structure all the steps needed for preprocessing. The preprocessing pipeline used for the dataset is shown in Figure 14.
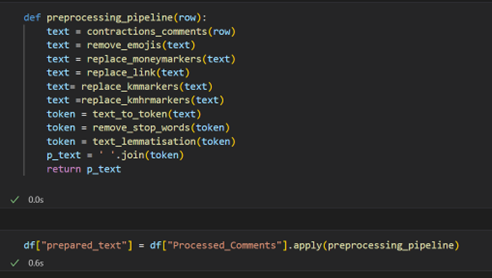
Figure: 14
Exploratory Data Analysis:
To understand the data better, exploratory data analysis was conducted.
Time Series Analysis:
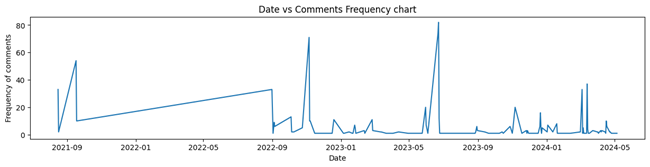
Figure: 15 A time series analysis of the date vs frequency of comments (Figure 15) is done. It indicates that we have a dataset from August 2019 to May 2024. Initially, there were very few comments, as when Ola launched its first electric scooter. From November 2022 to the present, comments have been posted frequently. Showing with time the number of customers is increased.
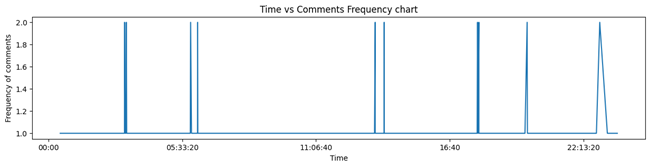
Figure 16:
Another time series analysis provides valuable insight into the Reddit use pattern. It shows customers of Ola electric scooters are primarily active in the evening and late at night.
Word Frequency Analysis:
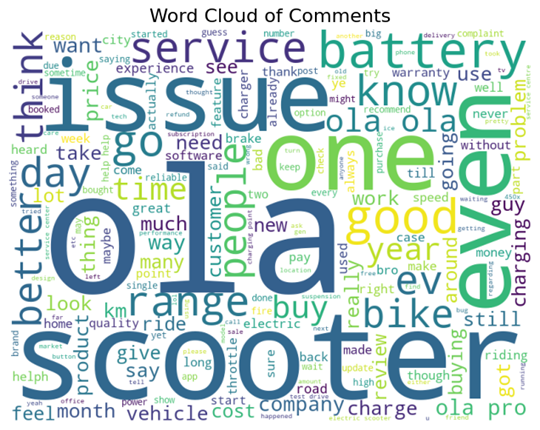
Figure: 17
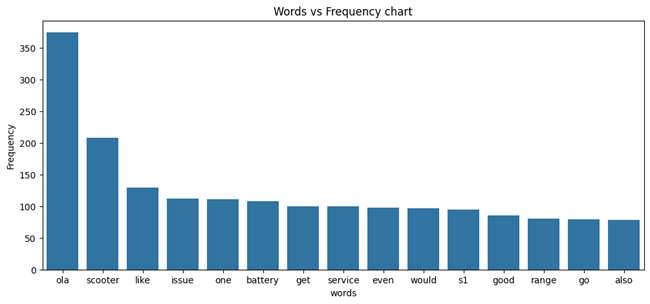
Figure 18
The word frequency analysis (Figure 17 & Figure 18) shows that the most common words in all the comments are Ola, Scooter, like, and issue. All the comments are relevant to the topic and likes, and problems are the most prominent words, indicating that customers share their experiences.
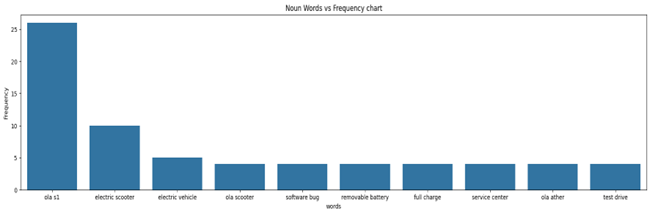
Figure: 19
Another analysis where the most frequent noun word pairs are analysed (Figure 19). This analysis reveals that Ola S1 is the most frequent, supporting our report’s aim. Other frequent pairs are software bugs, test drives showing customers facing software bugs in their scooters, and people interested in taking test drives. Another fascinating insight is the pair of Ola and Ather. This shows that customers also compare Ola scooters with its competitor, Ather.
Text Mining
Modelling and analysis of discussion themes and topic:
Latent Dirichlet Allocation (LDA) is used to understand and select only important discussion themes. LDA can identify latent topics discussed on Reddit. LDA is an unsupervised learning technique for discovering hidden thematic structures within a document collection. After Using LDA to find five hidden discussion themes (Figure 20), all topics of discussion are considered as all topics discussed Ola and its features or services.

Figure 20:
Modelling of owner sentiments and opinions:
Vader sentiment analysis is utilised to gauge the sentiment of customer opinions on the Ola S1. Vader is a lexicon-based sentiment analysis tool that scores the text on a scale from -1 (most negative) to +1 (most optimistic). In Figure 21, it is shown that the frequency of most of the comments is neutral, and there is more frequency of comments on the positive side than on the opposing side.
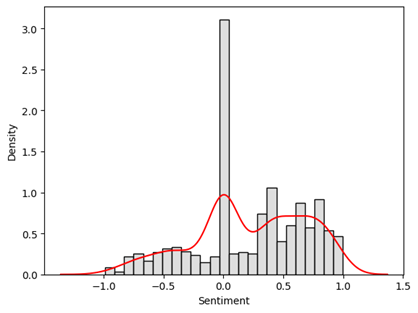 Figure: 21
Figure: 21
In Figure 22, it is shown that the average sentiment of all the comments is around 0.22, which means that overall, the comments are neutral and positive. The middle 50% of the data is strongly positive. In Figure 23, the sentiment statistics are compared with all the sub-discussion themes made using LDA. All the sub-discussion topics have different counts, showing that the data set is not balanced. There are 560 comments on sub-topic 1 and 76 comments for topic 2; the rest are below 50. Even with different comments count, all topics have a similar average sentiment. Figure 24 shows that for all the topics, the average sentiment is strongly positive for topics 2,3 and 4 (in graphs 1,2 and 3), indicating the comments where the discussion was about service, suspension and range of Ola S1 people showed fewer positive sentiments but when the debate was about battery and charging people showed more positive sentiments.
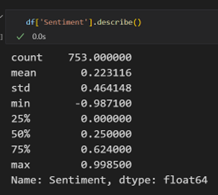 Figure: 22
Figure: 22
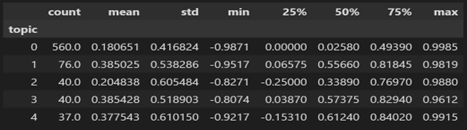 Figure: 23
Figure: 23
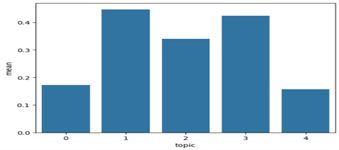 Figure: 24
Figure: 24
Model Evaluation:
To evaluate the model, 150 comments were manually labelled as positive, negative, and neutral, and then the model predicted the score for the same comments. Then, it is converted to positive, negative, and neutral, as shown in Figure 25. After that, the F1 score and Accuracy are calculated (Figure 26). The high F1 score indicates that the model has achieved high precision (few false positives) and high recall (few false negatives). At the same time, a High Accuracy score shows that the mode could predict the right sentiment most of the time. Here, the F1 score is quite a bit higher than the accuracy score, showing our data set is unbalanced. As we have already seen, there are primarily neutral comments, followed by positive comments and very few negative comments.
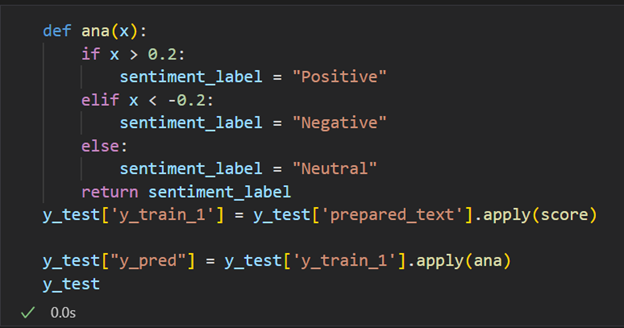 Figure: 25
Figure: 25
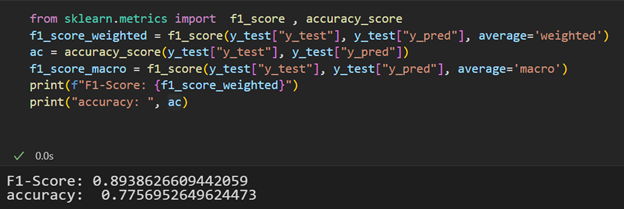 Figure: 26
Figure: 26
Conclusion
This report used Reddit data analysis to investigate customer sentiment regarding Ola Electric’s first scooter model. By analysing over 900 comments, we gained valuable insights into user experiences, common discussion topics, and overall sentiment. The analysis revealed a neutral sentiment with a slight positive leaning. While a significant portion of comments expressed satisfaction (“like”), some customers raised concerns (“issue”). Time series analysis indicated a rise in comments coinciding with increased customer adoption. Latent Dirichlet Allocation identified five key discussion themes: service, suspension, range, battery, and charging. Sentiment analysis within these themes showed generally positive feelings towards battery and charging, while service, suspension, and range elicited slightly less positive sentiment. The Vader sentiment analysis model achieved high F1 scores and accuracy, demonstrating its effectiveness in classifying comment sentiment. However, the data’s unbalanced nature, with a predominance of neutral comments, is acknowledged. This study provides a valuable snapshot of customer sentiment towards Ola’s first electric scooter. The findings can inform future product development, customer service strategies, and marketing efforts to address customer concerns and capitalise on positive experiences. Future research could explore sentiment across social media platforms and delve deeper into specific topics this analysis identifies.
References:
Bhalla, T. (2020) ‘Ola Electric acquires Etergo, looks to launch electric scooters in India by 2021’, mint,27 May. Available at: https://www.livemint.com/companies/news/ola-electric-acquires-etergo-looks-to-launch-electric-scooters-in-india-by-2021-11590576268370.html (Accessed: 25 April 2024).
CarDekho (2024) Upcoming OLA Electric Cars. Available at: https://www.cardekho.com/cars/OLA_Electric (Accessed: 25 April 2022).
Government of India Press Information Bureau (2023) Economic Survey 2022-23 - Press Information Bureau. Available at: https://static.pib.gov.in/WriteReadData/userfiles/file/EconomicSurvey2023Q44O.pdf (Accessed: 25 April 2024).
IndianWeb2 (2022) Ola Electric Invests in Israeli Battery-Tech Firm StoreDot. Available at: https://www.indianweb2.com/2022/03/ola-electric-invests-in-israeli-battery.html (Accessed: 25 April 2022).
Lidhoo, P. (2021) ‘The big electric scooter battle’, Fortune India, 27 April. Available at: https://www.fortuneindia.com/enterprise/the-big-electric-scooter-battle/105440 (Accessed: 25 April 2024).